

衰弱是老年人群健康不良结局的重要预测因素,但由于现有工具的复杂性和耗时性,对其进行常规评估仍然具有挑战性。
尤其是在慢性肾脏病(CKD)等复杂疾病人群中,亟需一种既能保持预测准确性又便于临床实施的简化评估工具。
2025年8月15日,中山大学附属第三医院学者基于NHANES+CHARLS+CHNS+中山大学附属第三医院CKD队列数据,在期刊《Journal of Translational Medicine》(医学二区Top,IF=7.5)发表了一篇题为:“Development and multi-cohort validation of a machine learning-based simplified frailty assessment tool for clinical risk prediction”的研究论文。
本研究旨在利用机器学习方法,从多队列数据中筛选关键变量,构建一个简化且高效的衰弱评估工具,用于预测衰弱状态及其相关临床结局(如CKD进展、心血管事件和全因死亡率),以提升其在真实临床场景中的适用性和可推广性。

公共数据库与孟德尔随机化公众号回复“ 原文”即可获得文献PDF等资料。想用NHANES发文,看看这个包含上百种NHANES指标数据的零代码分析平台!如感兴趣,请添加微信号:aq566665
数据来源
研究使用四个独立队列的数据:
美国国家健康与营养调查(NHANES, n=3,480)1999-2002年数据作为训练与内部验证集;
中国健康与养老追踪调查(CHARLS, n=16,792)2011年基线数据和中国健康与营养调查(CHNS, n=6,035)2009年基线数据,用于外部验证与心血管结局预测; 队列(SYSU3 CKD, n = 2,264)2011-2019年数据用于CKD进展与临床验证。
具体的研究思路
首先,从NHANES数据中初选75个潜在预测变量,通过五种特征选择算法(LASSO、VSURF、Boruta、varSelRF、RFE)进行筛选,确定核心变量集;
随后,比较12种机器学习算法在训练集(NHANES)、内部验证集(NHANES子集)和外部验证集(CHARLS、CHNS、SYSU3 CKD)上的性能;
最终,选择最优模型并进行临床验证与可解释性分析。
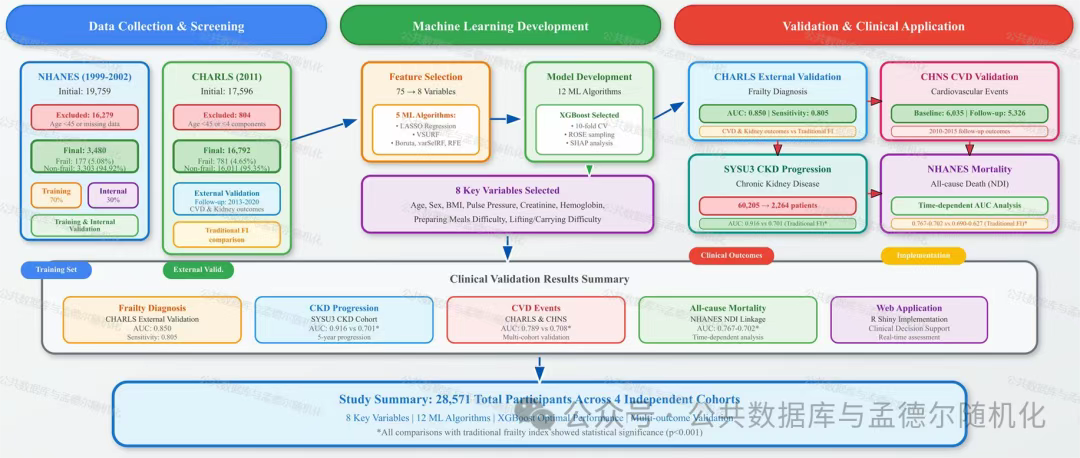
图1 基于机器学习的衰弱评估工具开发的综合方法论框架
主要研究结果
交叉分析结果显示,五种特征选择算法共同识别了8个核心变量——年龄、性别、BMI、脉压、肌酐、血红蛋白、备餐困难和提举困难。
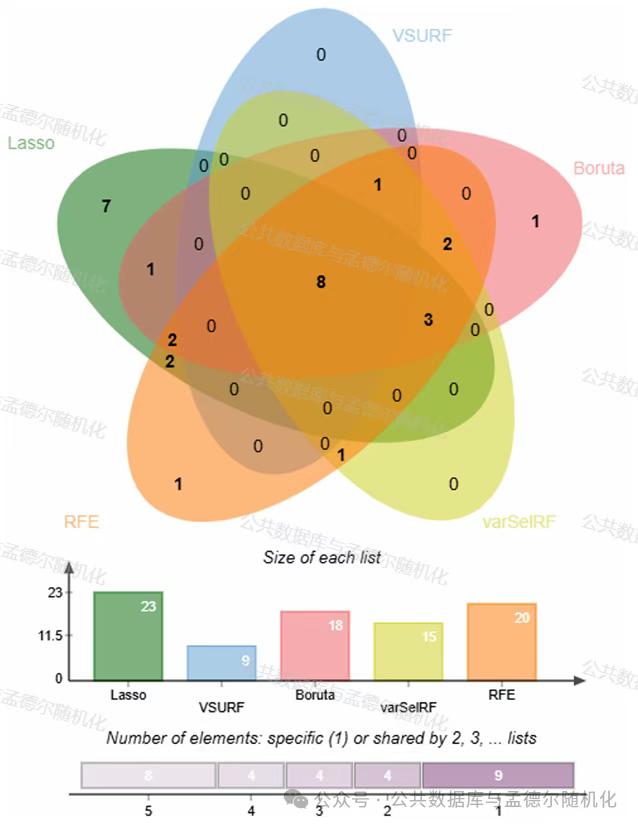
图2 五种机器学习算法所选特征的交集分析
随后,研究比较了12种机器学习算法的预测性能差异,结果表明,XGBoost模型在训练集、内部验证集和外部验证集中的AUC分别为0.963、0.940和0.850,显著优于传统衰弱指数(如对CKD进展的AUC为0.916 vs. 0.701)。
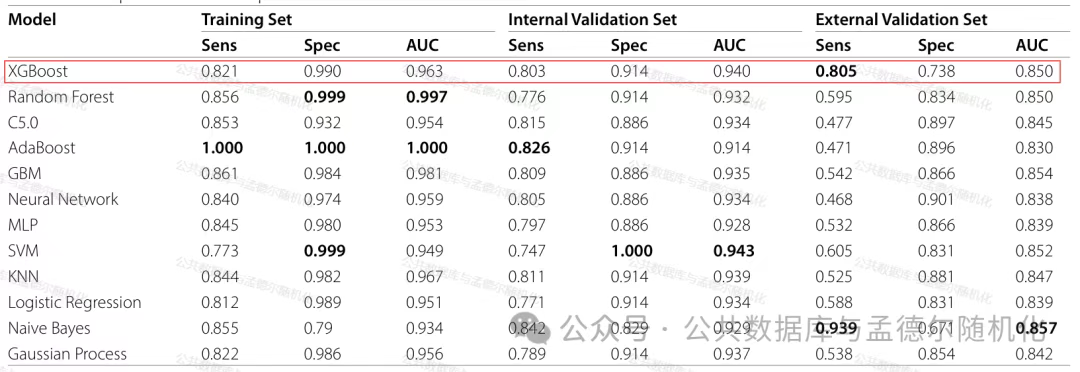
表1 不同数据集下模型性能指标的比较
同时,XGBoost模型在预测心血管事件(AUC 0.789)和全因死亡率方面也表现优异。
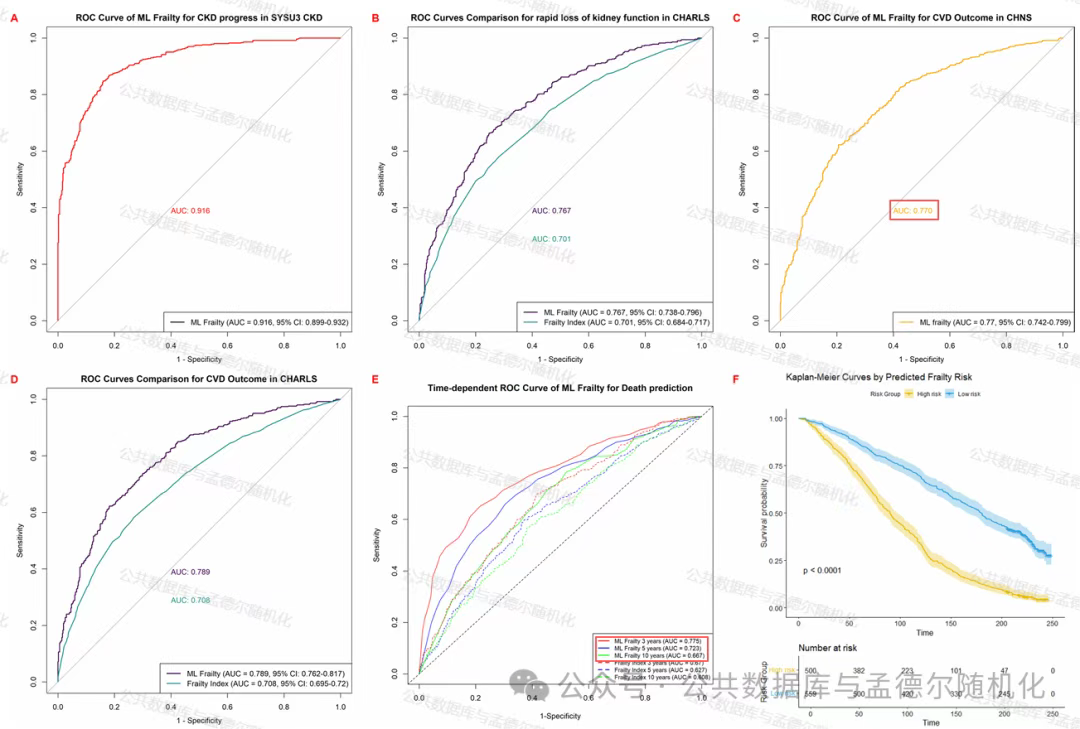
图3 机器学习衰弱模型在预测不同队列的多种健康结果中的临床效用
(A) SYSU3 CKD队列的CKD进展预测;(B)与传统衰弱指数预测CHARLS患者肾功能快速下降的比较;(C) CHNS患者心血管事件预测;(D)与传统衰弱指数比较CHARLS的心血管结局;(E)与传统衰弱指标相比,NHANES中随时间变化的死亡率预测;(F) Kaplan-Meier生存曲线按预测的衰弱风险类别分层
此外,SHAP分析进一步显示在上述变量中,功能能力变量(如提举困难)的贡献最大。
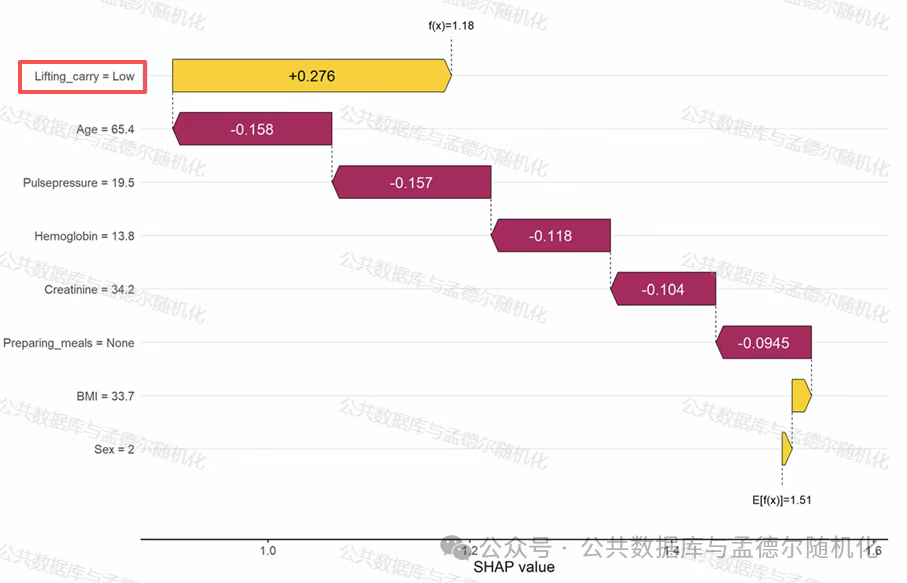
图4 特征变量的SHAP值及其对预测结果的影响
综上所述,本研究成功开发并验证了一个基于机器学习的简化衰弱评估工具,仅需8个易获取的临床变量即可实现高效的衰弱识别与多重健康结局预测。该工具在保持高预测性能的同时显著降低了临床评估负担,有望促进衰弱评估在常规临床实践中的推广应用。
-KnEP.png)