
今天,给大家介绍的是NHANES Online平台可分析的第 446个NHANES 稀有指标-----尼古丁代谢物比率 (NMR)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。
今天,给大家介绍的是NHANES Online平台可分析的第 450个NHANES 肥胖评估类指标-----脂肪质量指数(FMI)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。

近期,中山大学的学者在《Lancet Digital Health》(医学一区top,IF=24.1)上发表了一项研究,系统探讨了LLM能否帮助年轻研究者生成足够新颖且有用的临床科研思路。
今天分享一篇清华大学学者发表在《Scientific Data》(综合二区,IF=6.9)的研究文章,研究团队开发了一个名为WorldMove的全球人类移动数据集,完全免费开源,目前已覆盖179个国家和六大洲的超过1600个城市。

今天介绍CHARLS整理分析平台最新上线的CHARLS指标——非正式护理,相关研究已有18篇。

Logistic回归,统计分析的万金油!但有些情况,不再适合用logistic回归了,更推荐修正泊松回归。 诸位有没有这样的情况,只要一项医学研究,结局是二分类数据,第一下想到的肯定是logistic回归。确实,在现况调查、在病例对照研究、在队列研究、在随机对照研究都可以使用。
今天介绍CHARLS整理分析平台上线的CHARLS核心指标——肥胖与代谢状态,该指标用于精准区分不同代谢健康状态下的肥胖类型,相关高分研究已证实其在衰弱等衰老结局中的重要预测价值。
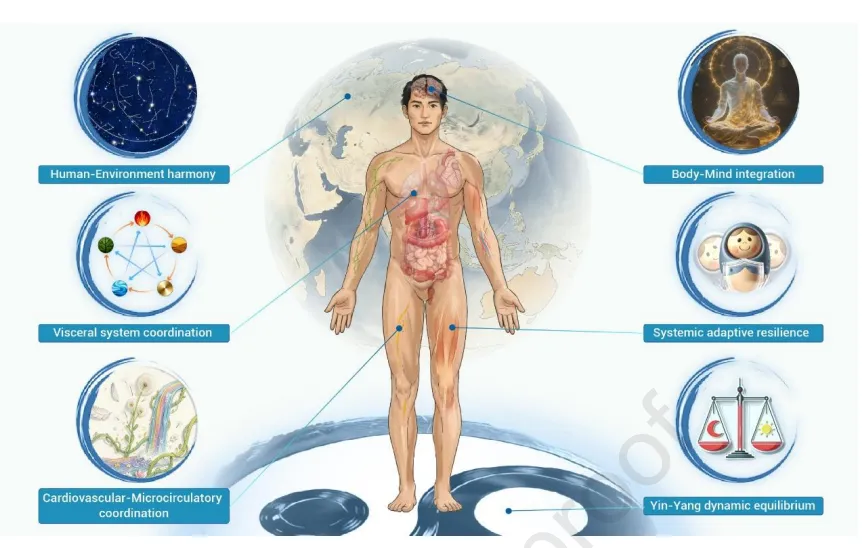
近期,福建中医药大学林尧教授与褚剑锋教授团队,联合南京中医药大学程海波教授团队、葛立林在国际顶尖期刊《The Innovation》(综合性期刊一区,IF=25.7)在线发表了一篇文章,题为“Hallmarks of health: A Chinese medicine perspective”。
近年来,有一个指标在 NHANES 研究中逐渐受到关注——健康社会决定因素(SDoH)。它不直接反映 “疾病本身”,却能够稳定关联死亡、心血管风险及多种慢性病结局,在不少高水平研究中都有应用。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

