
今天我们分享一篇发表在《Scientific Reports》的研究论文,研究团队旨在应用双重机器学习(DML)框架,探讨了司库奇尤单抗从150mg升至300mg对疾病活动度和生活质量的个体化因果效应。
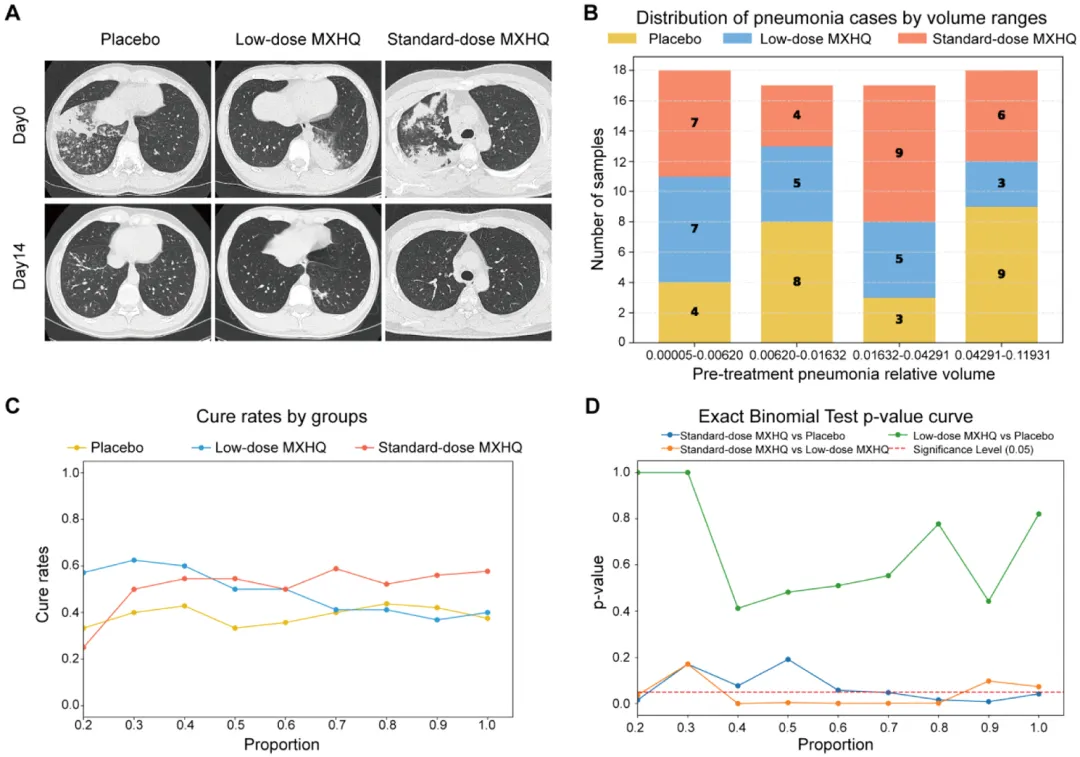
近期,广东省中医院潘胡丹教授团队开展了一项临床试验,试验成果发表在《Pharmacological Research》期刊(医学一区,IF = 10.5)上。 本研究旨在评估麻杏藿翘颗粒(MXHQ)作为莫西沙星辅助治疗在非重症社区获得性肺炎(CAP)中的疗效和安全性,同时探讨其潜在机制。

2026年4月15日,复旦大学附属儿科医院黄国英教授领衔,在医学顶刊《NEJM》(医学一区Top,IF=78.5)发表最新临床试验研究成果。 研究首次在中国的川崎病患者中,系统评估了在标准治疗(免疫球蛋白静脉注射(IVIG)+阿司匹林)基础上加用泼尼松龙(糖皮质激素)对冠状动脉病变的预防效果,结果为阴性但具有重要临床指导意义。

在观察性研究中,想要证明“老年人社交与上网能预防抑郁”并不容易。 尤其是老年人的身体状况、认知水平和社交行为随时间不断动态变化,互为因果。因此传统的回归分析往往难以处理这种“剪不断理还乱”的时间相关混杂。

逆概率加权(IPTW)方法已经是十分火爆了,作为倾向性得分方法的一种,应用也非常广泛,估计很多朋友都知道。 但广义逆概率加权方法,你可知道? 传统的逆概率加权方法用于暴露变量为二分类的情况,而广义逆概率加权方法则用于暴露因素为多分类或连续型变量的情况。

今天分享一篇基于自动机器学习(AutoML)与双重机器学习(DML)相结合的研究,作者系统评估了中国67个城市饮用水中ARGs的驱动因素,并实现了从“关联挖掘”到“因果验证”的完整分析框架。

大语言模型(LLM)正被越来越多地用于术前教育和出院指导,但它的效果到底如何?我们真的会评估吗? 北京协和朴美华教授护理团队本科生最新发表于《npj Digital Medicine》(Nature子刊 IF 15.1)的系统综述后发现:现有评估“偏科”严重——大家热衷测量焦虑和满意度,却几乎不关注模型的安全性、公平性和运行效率。该综述基于一个四维评估框架(准确性、可信度、共情、性能),系统分析了20项研究。
今天分享一篇发表在《Neurosurgery》(医学二区top,IF=3.9)的文章,研究团队评估了开放颅脑手术对儿童重型颅脑损伤(TBI)患者出院结局的影响。

中介分析想要做得好,时间顺序和因果逻辑必须理清楚。之前我们曾分享过一篇中介分析相关的文章,里面的思路非常清晰。 最近我们又看到一篇纵向研究,主要探讨了“感知到的虐待性监管如何通过去人性化影响医护人员的反生产工作行为”,研究设计同样规范,我们一起来看一下!

因果有向无环图(简称DAG)是临床研究中阐明因果假设的核心工具。它不靠统计软件自动“跑”出来,而是靠研究者基于背景知识手动“画”出来的。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式


