医学研究,特别是随机对照试验,置信区间非常重要。但它中文论文文献中被长期忽视,因而我今天特地来科普下。 统计分析结果中,P值很重要。人人都爱P值!但光光这个“屁用”的值是不够的。我一直在说,统计分析报告,要效应值、P值、置信区间三者皆具。 <
-chxh.jpg)
答案是显而易见的,错了! 还是有很多人在问我这个问题,为什么错了? 首先是显著性一词,英文的说法是significant,或者significa
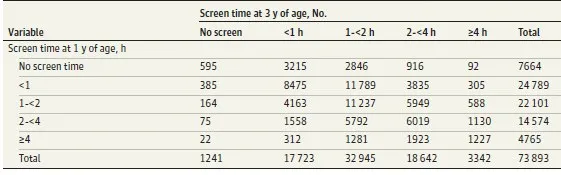
今日本公众号头条报道了一个关于电子屏幕与自闭症的关系! 里面介绍一个方法,Jonckheere-Terpstra方法。可能绝大多数人都没有听说过,这里做个简单介绍。


一直一直一直都在争议,当正态性检验,P值小于0.05,能否t检验问题,我已经写了类似的5篇文章。 有兴趣的话可以看一看!

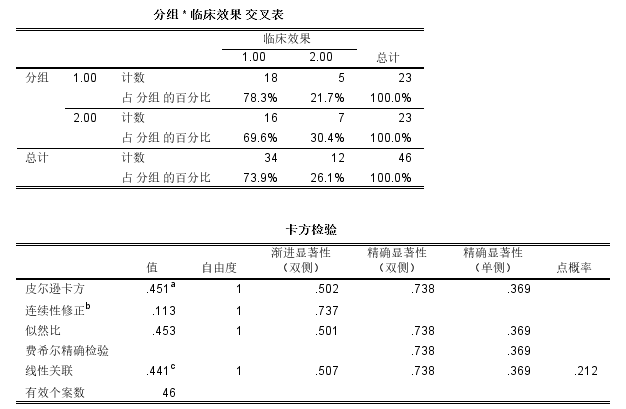
学统计学的都知道,多组均数的比较,可以考虑方差分析,方差分析以后要进行两两比较,。而两两比较不能直接采用两样本t检验,需要采用特别的手段控制一类错误(假阳性率)。 用什么方法呢?一般的医学统计学的教材会是三种方法,q检验(SNK法)、LSD检验,bonfferoni检验。SPSS软件包括了很多两两比

回归分析,无论是线性回归,还是logistic回归,都和线性方程有密切的关系,通过线性方程探讨自变X对因变量Y的作用。 线性回归方程
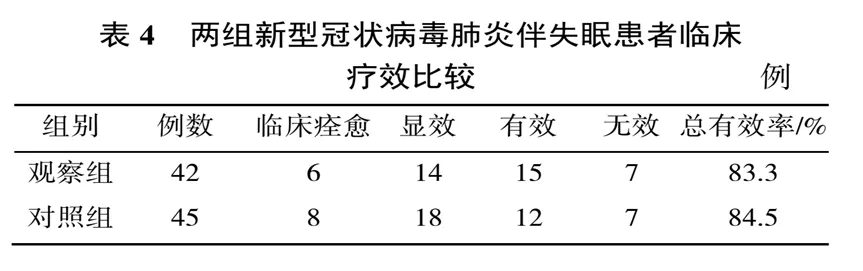
作为医学统计学老师,我参加了不少毕业论文的开题评审。很多学生往往要对问卷开展信效度分析。对于这一点,很多流统大咖表示不认同,他们基本认为只有量表才要做信效度分析,一般问卷是不需要做信效度的!
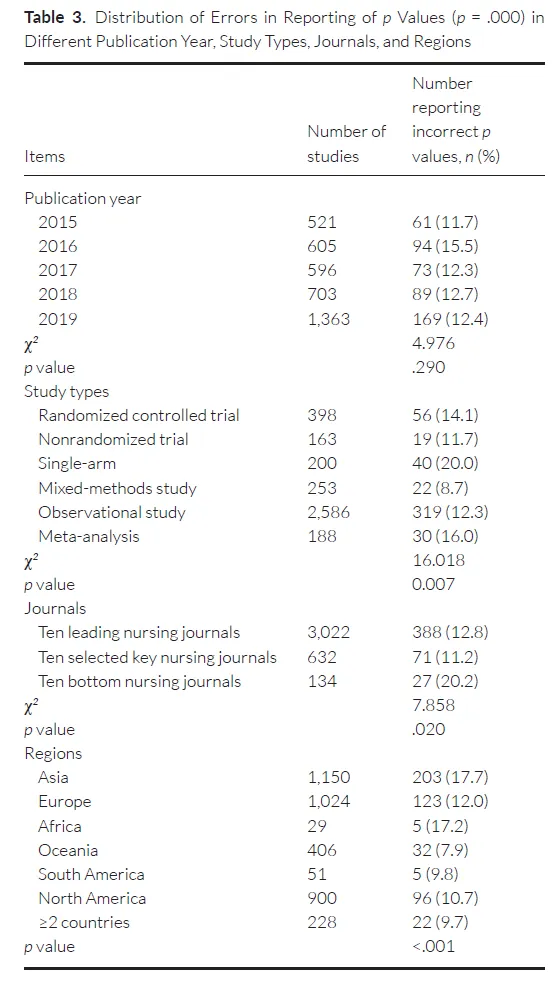
很多文章进行统计分析、撰写报告时,当P值比较小的时候(可能<0.000001 之类),由于软件的原因,把P值写成0.000(最常见的就是SPSS,一直都这么展现数据的)。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

