
中山大学医学学科最近几年发展迅猛。在2024年医学界的排名中,中山大学已经上升到第三位。 尤其是肿瘤学学科,特别是鼻咽癌防治领域,2023年还产生了一
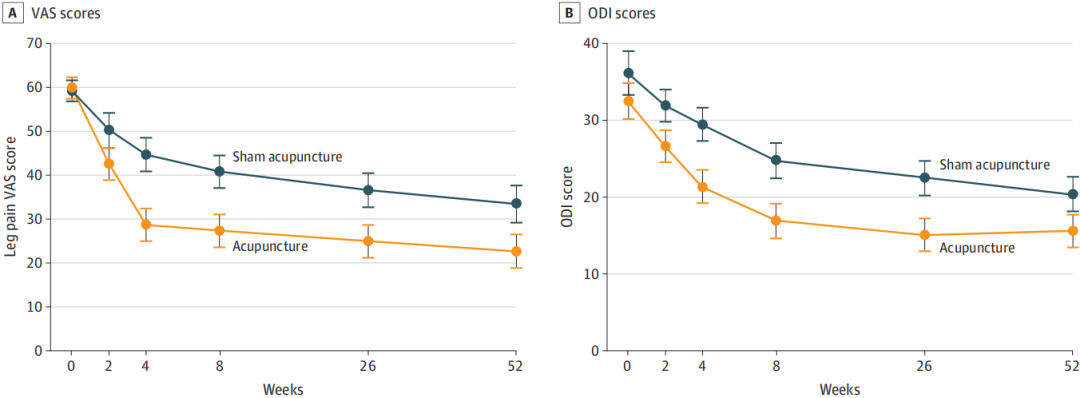
2024年10月14日,北京中医药大学刘存志教授团队,在医学顶级期刊JAMA子刊《JAMA Internal Medicine》(医学一区top,IF=22.5)上发表了题为
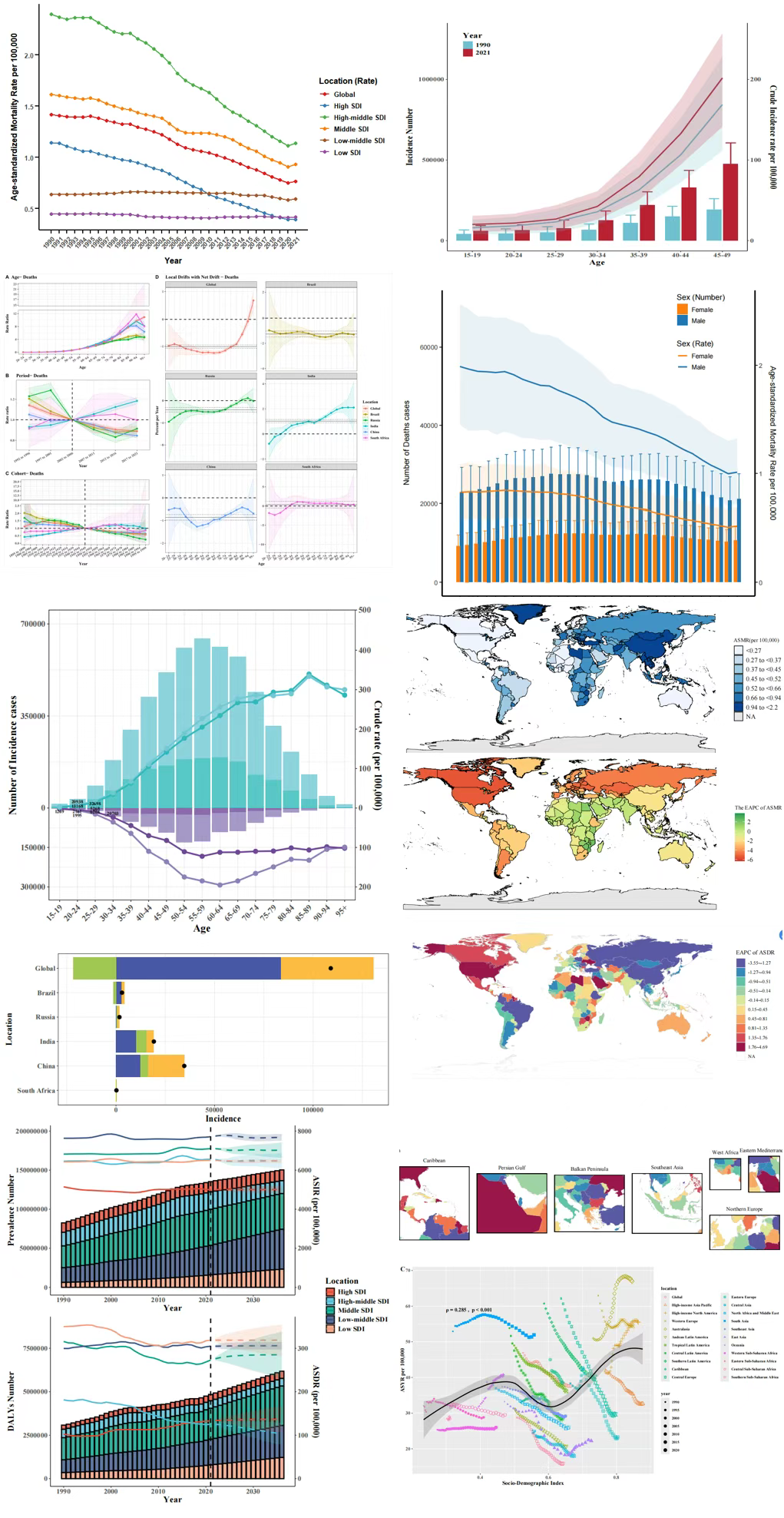
和团队成员一起,老郑我和同事陈老师一起团队们,搞了一个R语言包,用于全球疾病负担数据库(GBD)的分析。
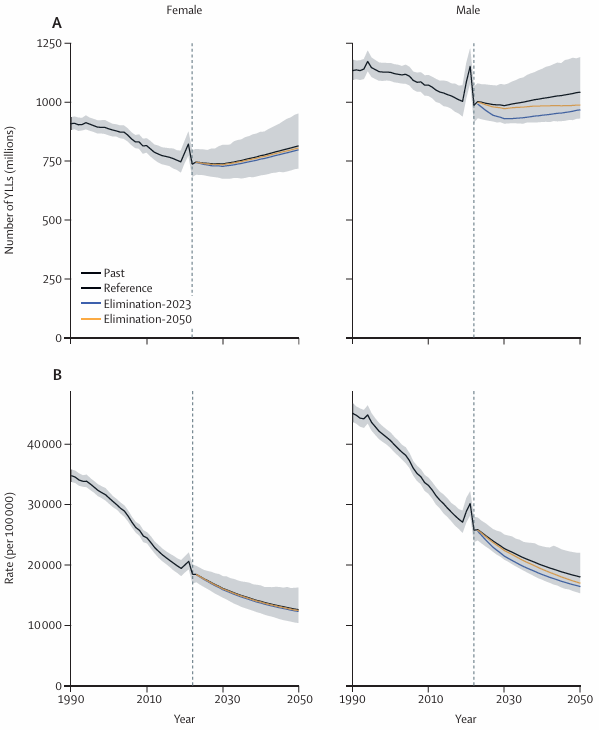
在当今社会,吸烟已成为全球范围内导致死亡的主要行为风险因素之一。据报道,从1990年~2021年间,吸烟已经导致超过1.75亿人死亡。面对这一严峻现实,如何有效降低吸烟率、减少其带来的健康危害,已成为各国政府和社会各界共同关注的重要议题。
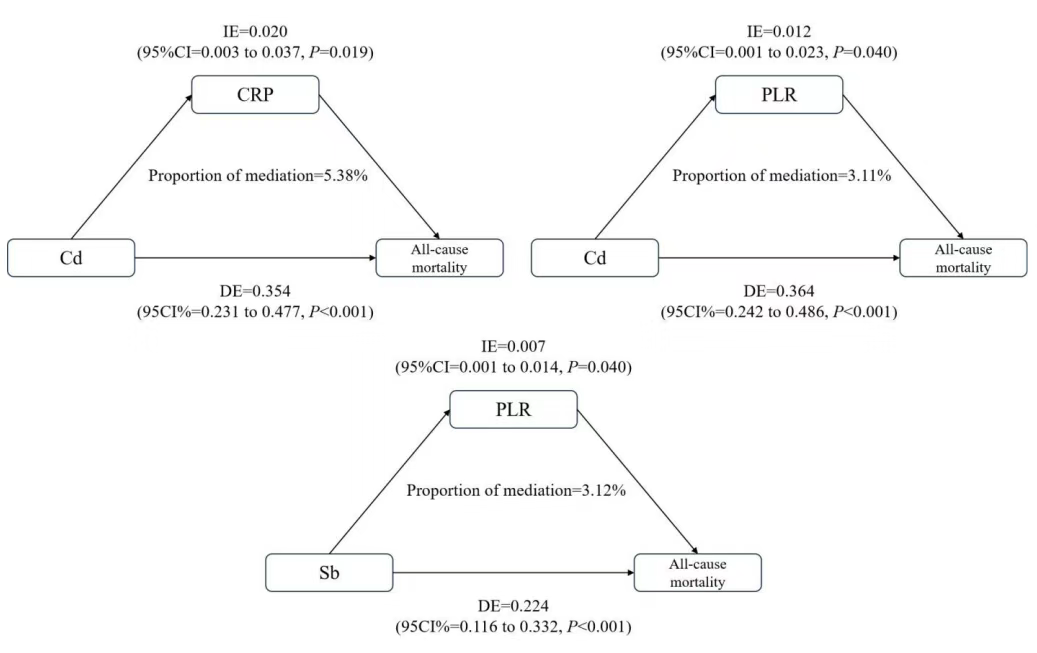
随着工业化的发展,废水和燃料尾气排放等工业活动显著增加了人类环境中重金属污染物的暴露水平,这些重金属在人体组织、器官中不断积累,对机体健康构成了严重威胁。
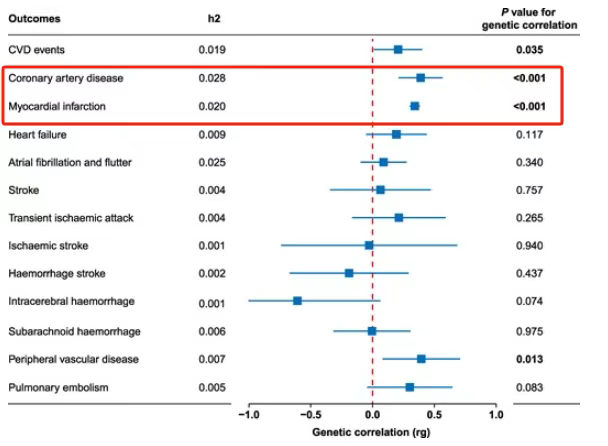
女性心血管疾病(CVD)是重要的公共健康问题,生育因素作为女性特有的风险因素,与CVD风险升高密切相关。妊娠期糖尿病(GDM)是女性妊娠期最常见的代谢紊乱,全球患病率为1.8%~31%。
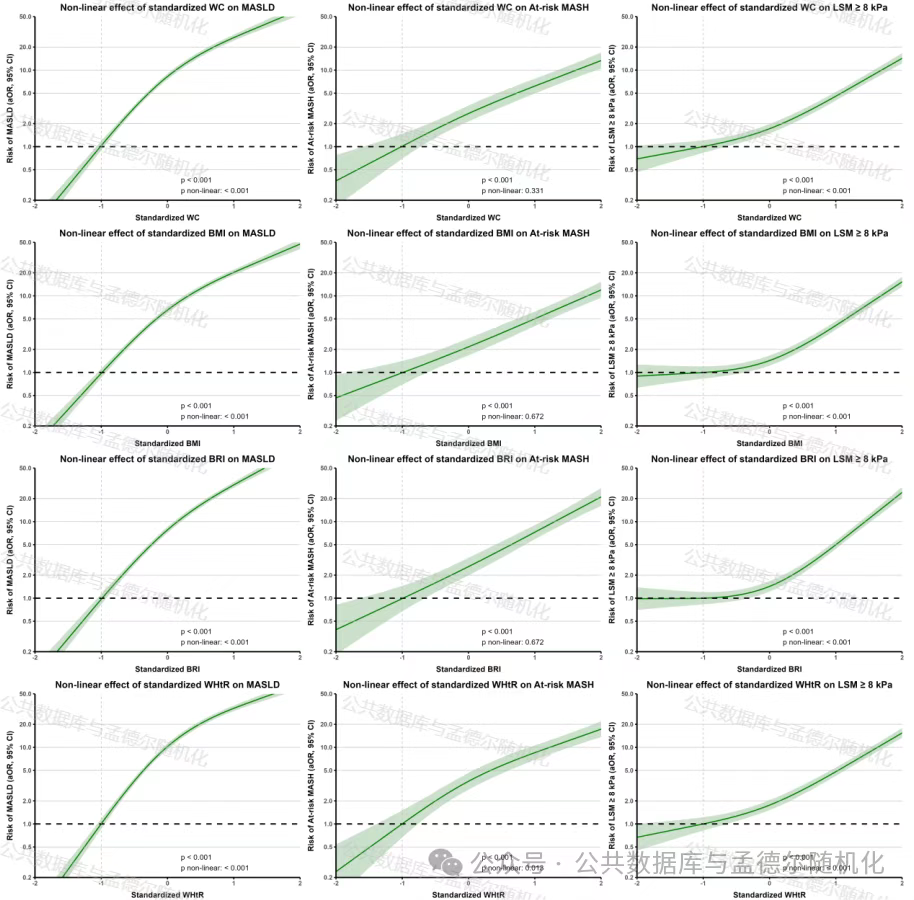
代谢功能障碍相关性脂肪性肝病(MASLD)已成为全球健康问题,约三分之一人群受其影响,其发展与内脏脂肪堆积密切相关。 传统指标如BMI无法准确反映脂肪分布,而腰围(WC)等参数可能更有效预测MASLD及其进展(如脂肪性肝炎[MASH]和肝纤维化)。 2025年7月23日,外国学者用NHANES数据库,在期刊《American Journal of Gastroenterology》(医学一区Top,IF=7.6)发表了一篇题为:“A comparison of the predictive value of 12 body composition markers for MASLD, at-risk MASH and increased liver stiffness in a general population setting”的研究论文,旨在评估12种身体成分标志物(如WC、腰高比[WHtR])、BMI等)对MASLD、高风险MASH和肝纤维化的预测价值,为临床风险分层提供依据。 研究结果表明,WC是预测MASLD及其并发症的最佳身体成分标志物,显著优于BMI及其他复合指数。
据世界卫生组织(WHO)及相关研究报告显示,中风已成为全球第二大死因,仅次于心脏病,给全球卫生系统带来了沉重的负担。此外,WHO提出的全民健康覆盖政策,进一步强调了不同地区和国家之间中风的不平等对于优化资源分配至关重要。
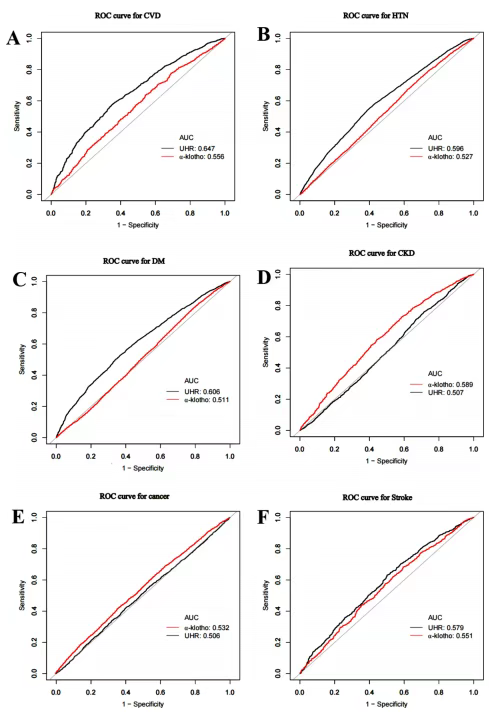
α-klotho是一种与抗衰老相关的蛋白质,其主要在肾脏中表达。先前的研究表明,循环中α-klotho水平较低与死亡风险增加相关,但这些研究忽略了炎症、代谢和激素等因素对其

早在19世纪,心理学家就提出听觉和视力与认知功能可能存在关联。随着时间的推移,科学家们逐渐发现听力和视力障碍这两种感觉障碍可能与痴呆高度相关。 <
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

